Self-Attention Generative Adversarial Networks (SAGAN; Zhang et al., 2018) are convolutional neural networks that use the self-attention paradigm to capture long-range spatial relationships in existing images to better synthesize new images. TDLS recently presented and discussed this paper, led by Xiyang Chen. The details of the event can be found on the TDLS website, and the full presentation can be viewed on YouTube. Here, we present an overview of the paper and its main contributions.
Challenges with Traditional GANs
While excellent at generating fairly realistic images, traditional deep convolutional GANs are unable to capture long-range dependencies in images. These conventional GANs work well for images that do not contain a lot of structural and geometric information (e.g., images depicting oceans, skies, and fields). However, when there is a high rate of information variation in an image, conventional GANs tend to miss out on obtaining all of this variation, and thus fail to represent the global relationships faithfully. These non-local dependencies consistently appear in certain classes of images. For example, GANs can draw animal images with realistic fur, but often fail to draw separate feet.
 Output images from the previous state-of-the-art GAN (CGANs with Projections Discriminator; Miyato et al., 2018)
Output images from the previous state-of-the-art GAN (CGANs with Projections Discriminator; Miyato et al., 2018)
Given the limited representation capacity of the convolution operator (i.e., the receptive field is local), conventional GANs can only capture long-range relationships after several convolutional layers. One approach to alleviating this problem is to Increase the size of the kernel, but this is statistically and computationally inefficient. Various attention and self-attention models have been formulated to capture and use structural patterns and non-local relationships. However, these models are generally not effective in striking a balance between computational efficiency and modeling long-range relationships.
Self-Attention for GANs
This functional gap is where SAGAN comes in. Zhang et al. (2018) propose a method wherein the GAN model is equipped with a tool to capture long-range, multi-level relationships in an image. This tool is the self-attention mechanism. Self-attention attempts to relate different portions of the input features to compute another representation of the input suitable for the task at hand. The idea of self-attention has been successfully applied in the areas of reading comprehension (Cheng et al., 2016), textual entailment (Parikh et al., 2016), and video processing (X. Wang et al., 2017).
Bringing self-attention to the image synthesis domain draws inspiration from “Non-local neural networks” (X. Wang et al., 2017) that use self-attention to capture spatial-temporal information in video sequences. Generally speaking, self-attention simply calculates the response at a single position as a weighted sum of the features at all positions. This mechanism allows the network to focus on areas of images that are widely separated yet have structural relevancy.
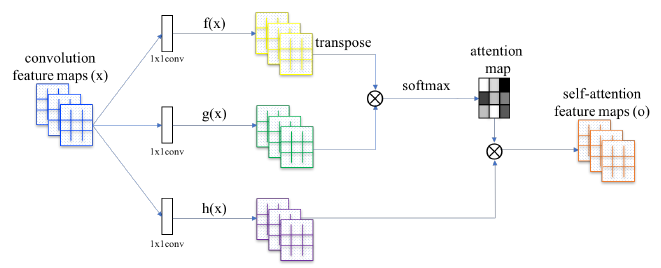 The proposed self-attention module in Self-Attention Generative Adversarial Networks (Zhang et al., 2018)
The proposed self-attention module in Self-Attention Generative Adversarial Networks (Zhang et al., 2018)
In SAGAN, the self-attention module works in conjunction with the convolution network and uses the key-value-query model (Vaswani, et al., 2017). This module takes the feature map, created by the convolutional neural network, and transforms it into three feature spaces. These feature spaces, called key f(x), value h(x), and query g(x), are created by passing the original feature map through three different 1x1 convolution maps. Key f(x) and query g(x) matrices are then multiplied. Next, the softmax operation is applied on each row of the multiplication result. The attention map generated from softmax identifies which areas of the image the network should attend to, as described in Equation (1) from Zhang et al. 2018:
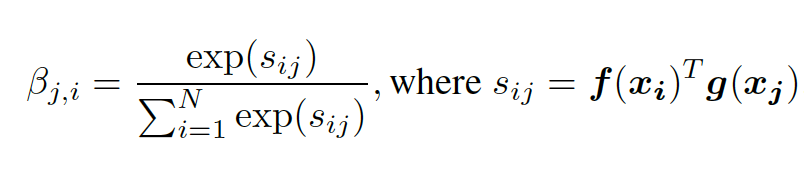
Therefore, the attention map is then multiplied with value h(x) to generate the self-attention feature map as follows (equation (2) from Zhang et al. 2018):
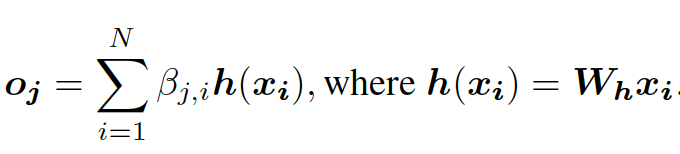
Finally, the output is calculated by adding the original input feature map to the scaled self-attention map. The scaling parameter 𝛄 is initialized to 0 at the beginning to cause the network to first focus on the local information. As the scaling parameter 𝛄 gets updated during training, the network gradually learns to attend to the non-local areas of an image (Equation (3) from Zhang et al. 2018):
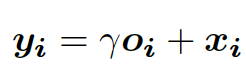
 Output images from Self-Attention Generative Adversarial Networks (Zhang, et al., 2018)
Output images from Self-Attention Generative Adversarial Networks (Zhang, et al., 2018)
Handling Instability in GAN Training
Another contribution made by the SAGAN paper is related to the well-known issue of the instability of GANs’ training. The paper proposes two techniques to handle this problem: Spectral normalization and Two Time-scale Update Rule (TTUR).
Generators are shown to perform better and have improved training dynamics when they are well-conditioned (Odena, et al., 2018). With SAGANs, generator conditioning is accomplished using spectral normalization. This approach was first introduced in (Miyato et al. 2018), but for the discriminator network only, to address training dynamics that may result in the generator not learning the target distribution well. SAGAN employs spectral normalization in both the generator and the discriminator network, limiting the spectral norm of the weight matrices in both of the networks. This process is beneficial because it constrains the Lipschitz constant without requiring any hyper-parameter tuning, prevents the escalation of parameter magnitudes and unusual gradients, and allows for fewer discriminator updates compared to the generator.
In addition to spectral normalization, the paper uses TTUR (Heusel et al., 2018) to address the problem of slow learning with regularized discriminators. Methods using regularized discriminators generally require multiple discriminator updates per generator update. To accelerate the learning speed, the generator and the discriminator are trained with different learning rates.
Conclusion
SAGAN is a substantial improvement to the state of the art for image generation techniques. The effective integration of the self-attention technique enables the network to faithfully capture and relate long-range spatial information in a computationally efficient manner. The use of spectral normalization in both the discriminator and the generator network, along with TTUR, not only reduces the computational cost of training, but also improves the training stability.